Consult the complete code here:
Introduction
Machine learning algorithms have been extensively used to predict loan credit risk in the context of consumer loans. Educational loans are similar to consumer loans in many respects, but they have some unique features, such as increased uncertainty about the borrower’s characteristics at the time of repayment. In Brazil, the most prominent educational loan program is FIES (Financiamento Estudantil). Its objective is to provide students from low socioeconomic backgrounds with loans to pay for university tuition fees.
We used a database that contains information about more than 600,000 students who got the loan from the FIES program. Each line of the data set corresponds to one contract and includes information regarding the compliance with the loan, amount of days of no compliance with the payment, and a dummy for loan default. Besides, for every contract, there is information about each student such as family income, whether she has a job, gender, race, which course she is taking, marital status, whether the student went to public high school or not, and so on. Each one of these variables is a possible predictor of loan default. The data sources are the Ministry of Education and financial institutions that operate the loan; the Brazilian National Treasury compiled the final database.
As expected, our results show that an ensemble model is better able to provide accurate classification. Our ensemble model outperforms all non-ensemble models. Loan value-related features are the most important predictors of loan default in our model. This might be a source of bias if we consider that subgroups who hire specific loan values might be included or excluded from the program if our model is employed.
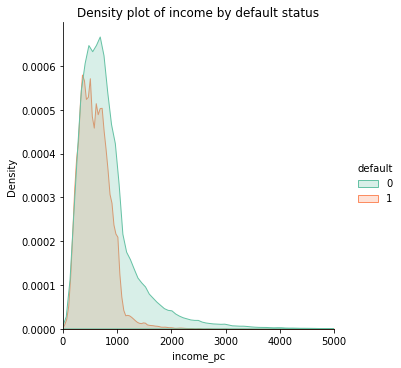
Data set exploration
Bellow, some plots explore the characteristics of the dataset.
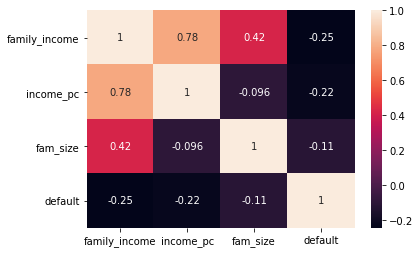
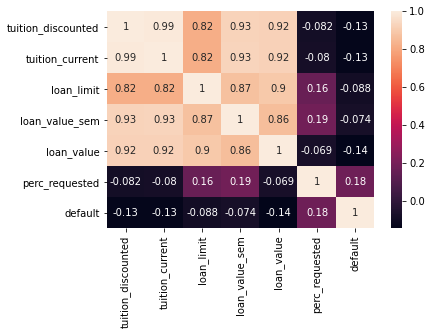
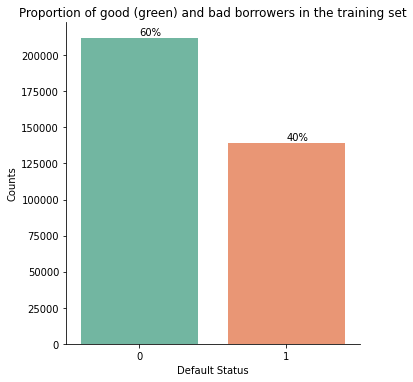
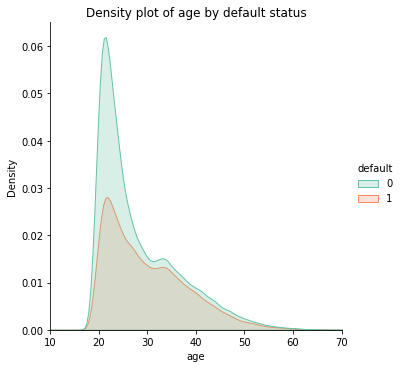
Best individual models
After fine tunning our individual models, the models presented the following AUC scores:
| Model | AUC |
|---|---|
| ANN | 0.816213 |
| Random Forest | 0.775061 |
| Logistic Regression | 0.722902 |
| Linear SVC | 0.672063 |
| Decision Tree | 0.634598 |
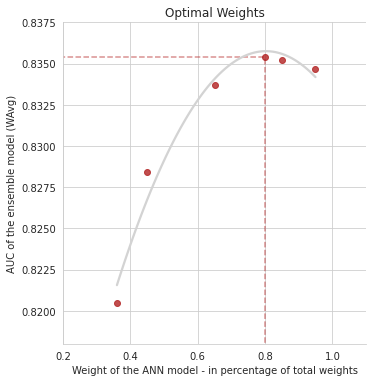
Ensemble Model
At this point we developed an ensemble model, that consisted of the weighted average of the three best individual models (ANN, Random Forest and Logistic Regression). In the graph bellow we illustrate the search for the optimal weights to calculate the weighted average of our final model.
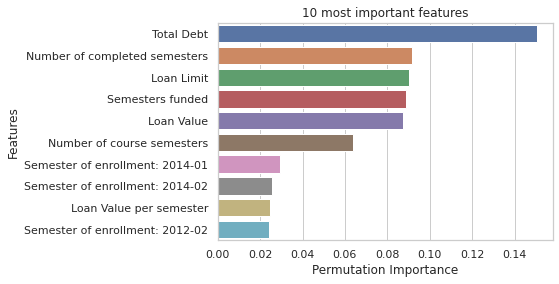
Feature Importance
Total debt is the most important predictor in our ensemble model. It contains information on the total value of the debt of a certain student. It is related to which course the student chose, since some courses, like Medicine, are more expensive. It is also related to other features that also ap- pear among the most important, like semesters funded, loan value, loan limit and loan value per semester. Our model is, therefore, strongly driven by the amount of money hired by the student.
Results
The final result was better than expected for the classification task. We outperformed chosen benchmark reference (Random Forest) by almost 6.6%. Moreover, if we had used logistic regression as our baseline, as many authors do for type of classification, then we would have obtained a 15.5% improvement.
*Many thanks to Carol Sobral and Diego Faria for the partnership in this rewarding project.